Introducing BIOS
A world-class AI scientist built to accelerate scientific discovery.

Today we're launching BIOS, a powerful AI Scientist. BIOS coordinates specialized subagents for literature search and data analysis, planning and executing multi-step research workflows while you steer.
State-of-the-art performance
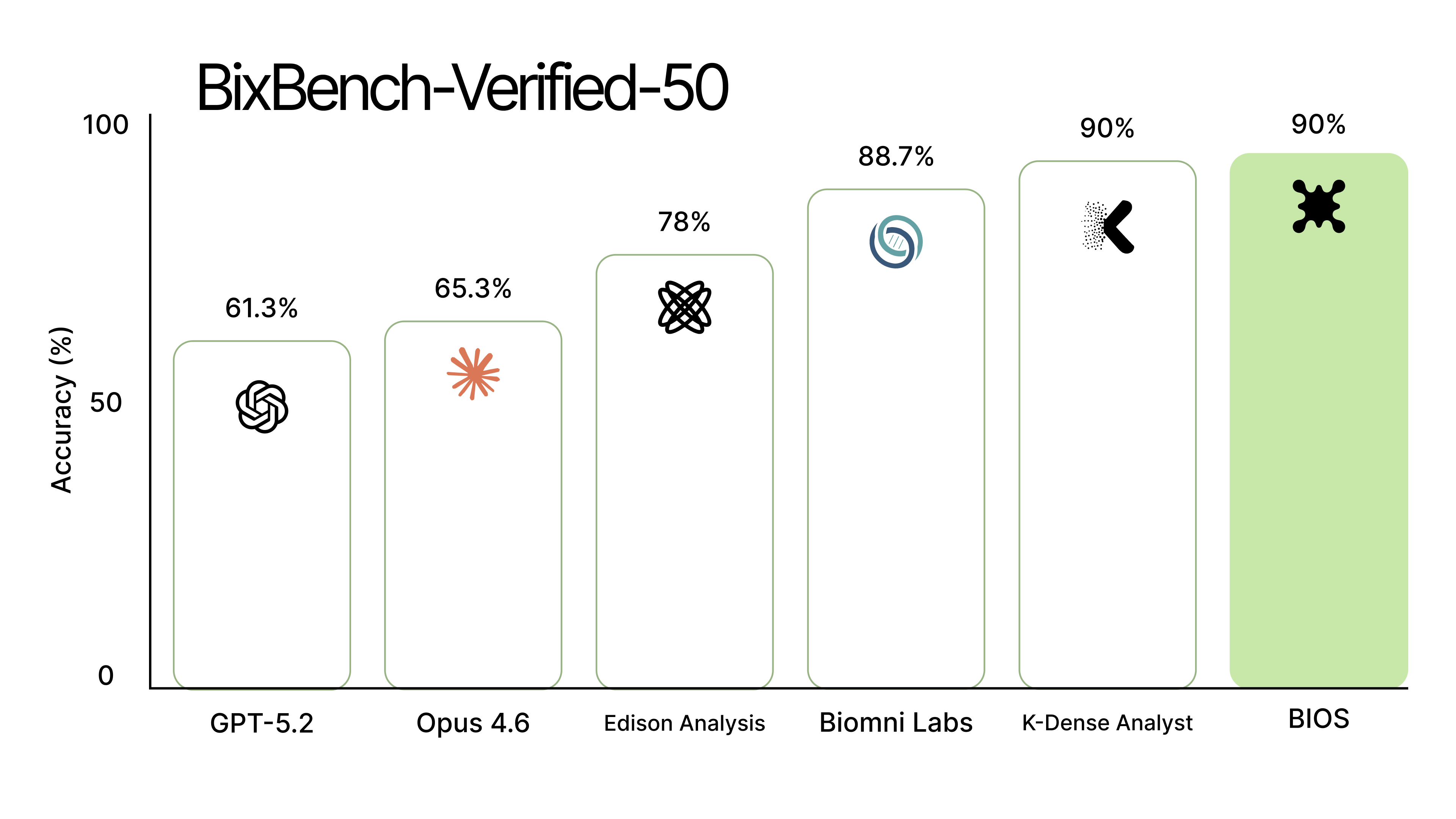
BIOS's analysis capabilities rank #1 on BixBench, a challenging bioinformatics benchmark. BixBench tests real-world analytical scenarios spanning genomics, transcriptomics, differential expression, and more—tasks that require executing complete analysis workflows, not just answering from memory.
BIOS achieves state-of-the-art performance across all three evaluation modes: 48.78% on open-answer, 55.12% on multiple-choice with refusal, and 64.39% on multiple-choice without refusal—outperforming Edison, K-Dense, Kepler, and GPT-5.
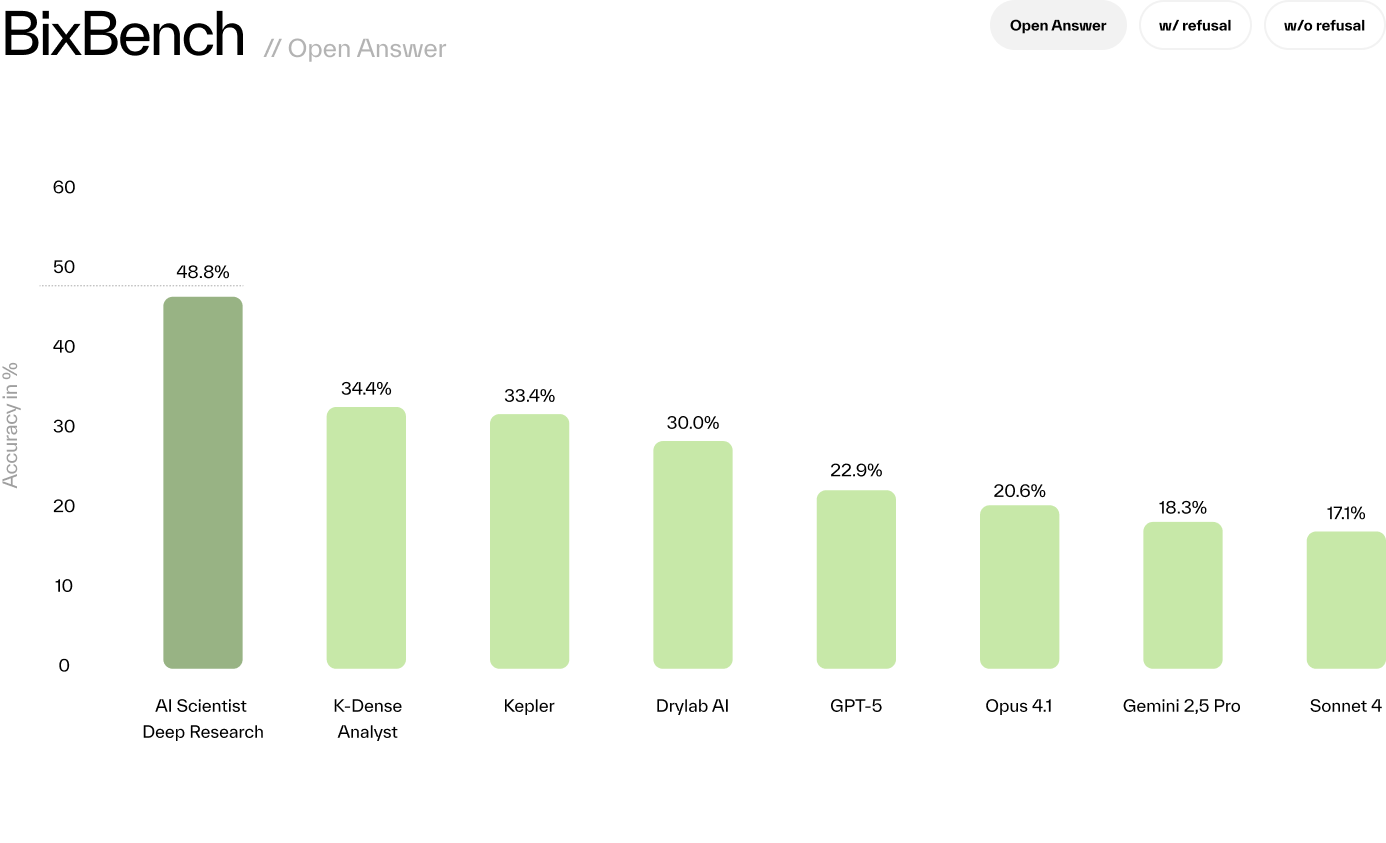 BIOS achieves 48.78% accuracy on BixBench open-answer questions, outperforming K-Dense (34.4%), Kepler (33.4%), and GPT-5 (22.9%).
BIOS achieves 48.78% accuracy on BixBench open-answer questions, outperforming K-Dense (34.4%), Kepler (33.4%), and GPT-5 (22.9%).
Full benchmark results are available in our results spreadsheet. For methodology and detailed analysis, see our paper on arXiv.
How it works
BIOS is powered by Deep Research, an iterative workflow that completes research cycles in minutes rather than hours. Where batch-processing systems like Kosmos require extended runtimes before producing results, Deep Research lets you steer the investigation as insights emerge.
Each cycle follows three phases: Plan, Execute, and Refine. The planning phase breaks your research question into concrete tasks. Execution delegates those tasks to specialized subagents in parallel. Reflection synthesizes the results, updates the working hypothesis, and proposes next steps.
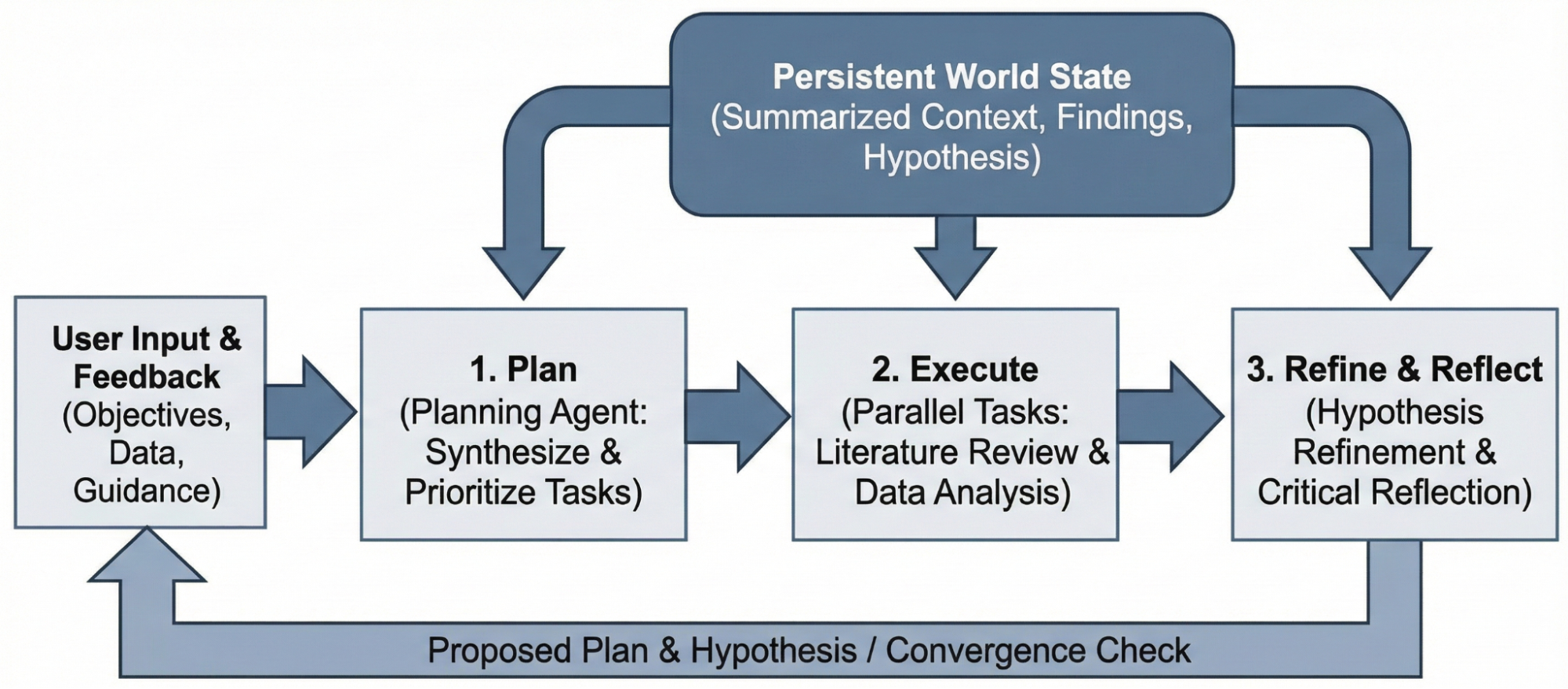 The Deep Research workflow: planning breaks down complex questions, execution delegates to specialized subagents, and reflection synthesizes results and identifies gaps for further investigation.
The Deep Research workflow: planning breaks down complex questions, execution delegates to specialized subagents, and reflection synthesizes results and identifies gaps for further investigation.
Central to this is the persistent world state—a structured representation of everything the system has learned: your research objective, current hypothesis, documented discoveries, key insights, and available datasets. Rather than losing context as conversations grow, the world state ensures each cycle builds meaningfully on prior work.
Four specialized agents power the system:
- Planning Agent — decomposes complex questions, prioritizes tasks, and proposes follow-up investigations
- Literature Agent — searches and synthesizes across papers, patents, clinical trials, and databases
- Data Analysis Agent — generates and executes Python code for statistical analysis and visualization
- Novelty Detection Agent — evaluates whether proposed hypotheses have been previously investigated
You can run in semi-autonomous mode with human checkpoints, or fully autonomous mode for extended investigations. Either way, you stay in control of the research direction.
Literature Agent
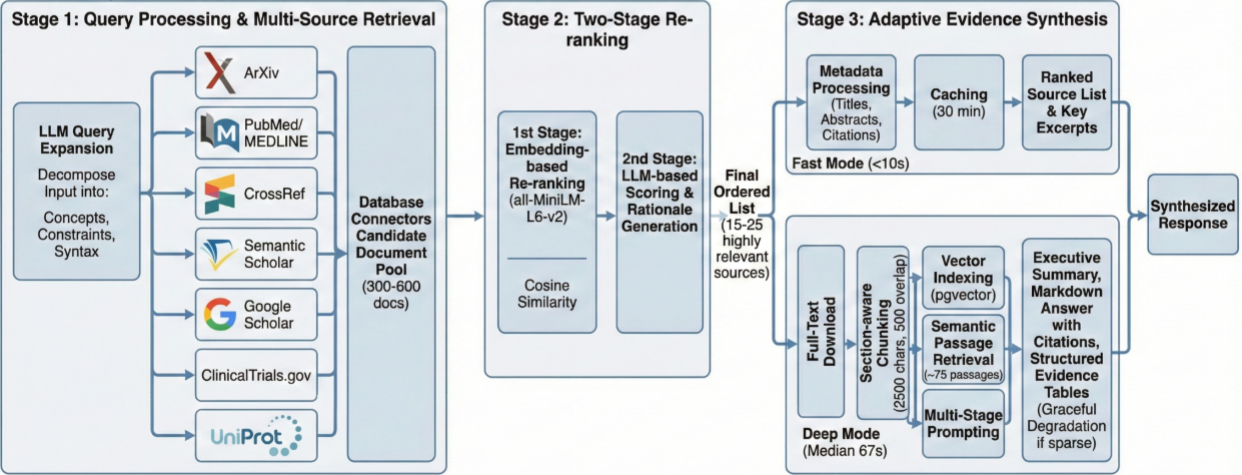
The Literature Agent synthesizes scientific knowledge through a three-stage pipeline. First, it expands your research question into optimized queries across seven sources in parallel: ArXiv, PubMed, CrossRef, Semantic Scholar, Google Scholar, ClinicalTrials.gov, and UniProt. Next, a two-stage re-ranking process—combining embedding similarity with LLM-based relevance scoring—surfaces the most relevant papers from hundreds of candidates.
 Literature Agent pipeline
Literature Agent pipeline
Two modes support different workflows. Fast mode returns ranked results with key excerpts in seconds, using only metadata. Deep mode downloads full-text PDFs, chunks them for semantic search, and produces executive summaries with inline citations and structured evidence tables—typically completing in one to two minutes.
Data Analysis Agent
The Data Analysis Agent handles complex analytical tasks through iterative code generation and execution. Given a task and dataset, it decomposes the problem into sequential steps, writes Python code to execute each step, observes the results, and reflects on what it learned. When code fails, bounded retries with error feedback allow the agent to self-correct.
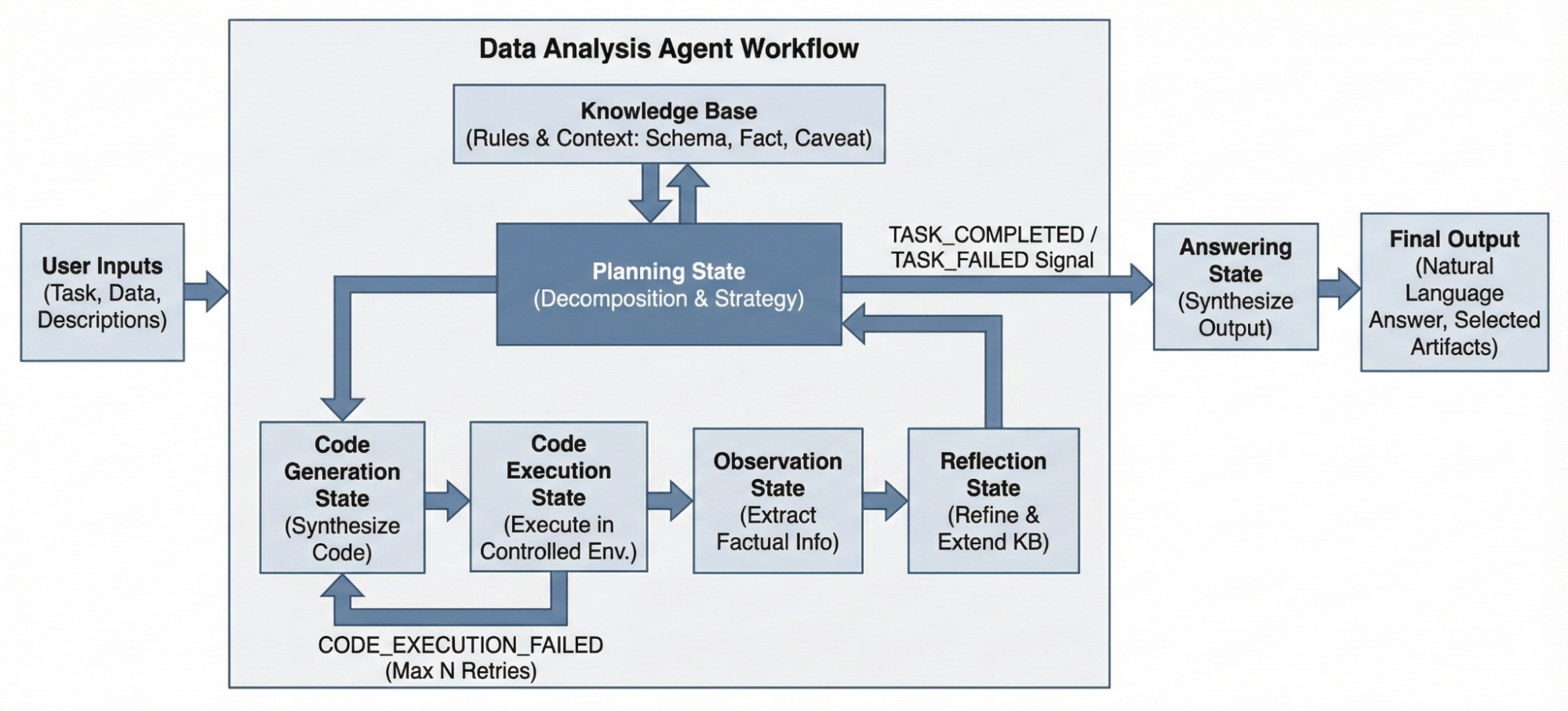 The Data Analysis Agent generates and executes Python code for statistical analysis and visualization, maintaining a persistent knowledge base that accumulates findings across research iterations.
The Data Analysis Agent generates and executes Python code for statistical analysis and visualization, maintaining a persistent knowledge base that accumulates findings across research iterations.
Central to its reliability is a persistent knowledge base that accumulates two types of findings: rules extracted from documentation and domain conventions, and context items capturing schema definitions, computed facts, and data quality caveats discovered during execution. This structured memory ensures the agent doesn't repeat mistakes and can tackle multi-step analyses that require building on intermediate results.
Case study: Multi-dataset integration
BIX-8 from the BixBench suite tests whether an agent can perform end-to-end statistical reasoning on a real computational biology problem: analyzing RNA m6A methylation patterns in bladder cancer. The task requires constructing contingency tables from methylation and expression data, computing derived quantities like hypermethylation ratios, and running chi-square independence tests to obtain test statistics, odds ratios, and p-values.
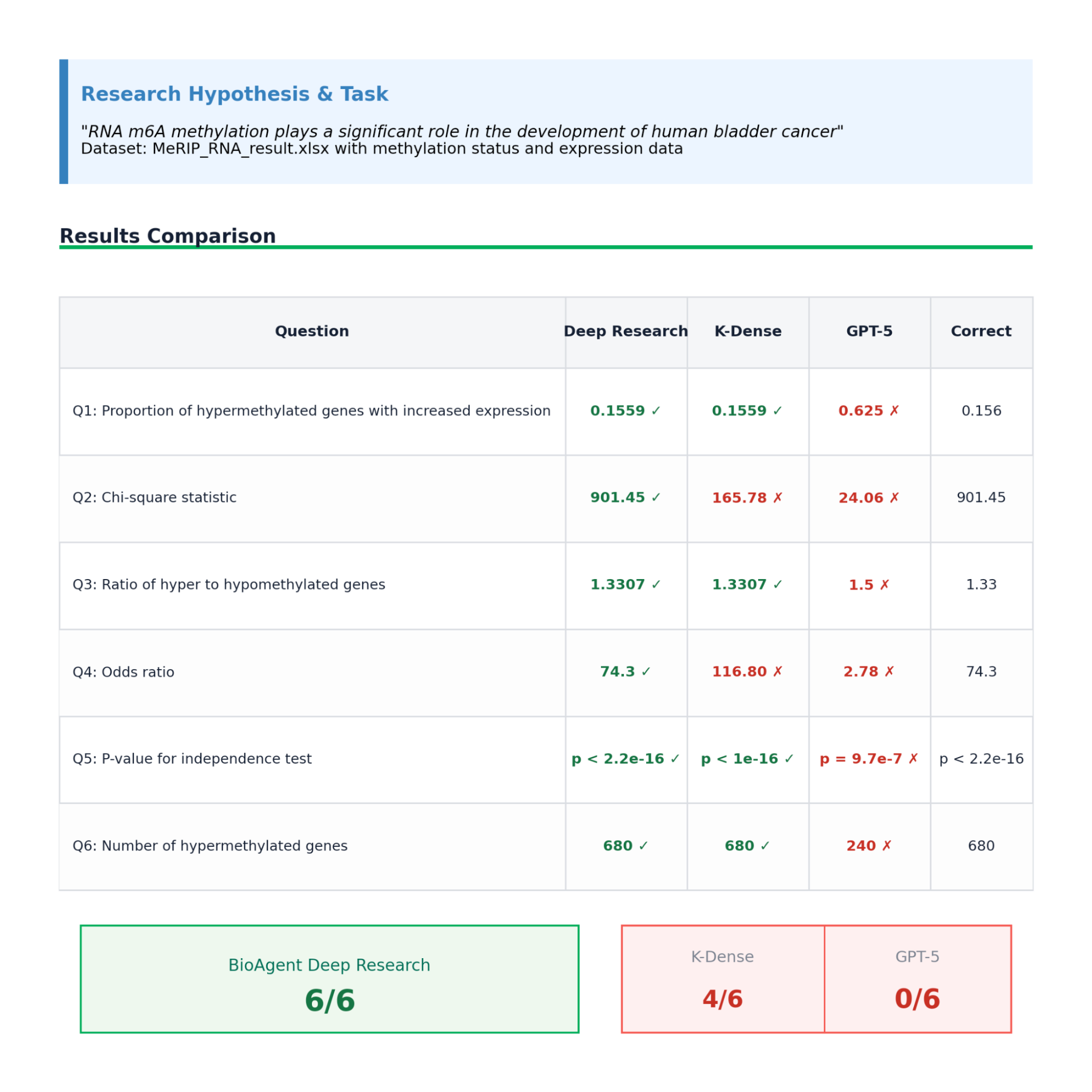 On BIX-8, a complex case requiring multi-dataset integration and statistical analysis, BIOS correctly answered 6/6 questions compared to 4/6 for K-Dense and 0/6 for GPT-5.
On BIX-8, a complex case requiring multi-dataset integration and statistical analysis, BIOS correctly answered 6/6 questions compared to 4/6 for K-Dense and 0/6 for GPT-5.
BIOS correctly answered all six sub-questions. K-Dense achieved partial success (4/6), while GPT-5 failed to recover any of the required quantities (0/6). This illustrates that our performance gains come from correct data structuring and statistical execution—not from relying on answer-option priors or surface-level pattern matching.
We'll be publishing more case studies in the coming months, including laboratory validation of discoveries generated by BIOS.
Subagents Built on BioAgents
BIOS is built on top of BioAgents, our open-source framework for building scientific agents. In the future, BIOS can eventually provide the orchestration layer that coordinates specialized subagents—handling the complexity of planning, delegation, and synthesis, so each subagent can focus on its domain.
Subagents can specialize in a specific research function, like literature review or data analysis, as well as a research domain, such as apoptosis or microbiology. The longevity-focused scientific agent, Aubrai, is built on the BioAgent stack and in the future will be integrated with BIOS as a subagent.
The core infrastructure of the BioAgents framework is public, and we welcome researchers and developers to build their own scientific agents or subagents, or contribute to ours.
The Literature and Data Analysis agents are not yet open source, but we're working on providing API access in the near future.
What will you discover?
BIOS is available now. Try it here. For a limited time, we are offering free, full access to academic users with a .edu email address.
BIOS is developed by the Bio Protocol AI team. Bio Protocol builds infrastructure for decentralized science.